Symbolica's Agentica SDK demonstrates a 36.08% unverified performance on the ARC-AGI-3 benchmark [1], successfully solving 113 of 182 playable challenges and completing 7 of 25 available game scenarios [2].
This implementation significantly surpasses Chain-of-Thought baseline results—Opus 4.6 Max at 0.2% and GPT 5.4 High at 0.3%—while delivering substantially better cost efficiency: Agentica achieves 36.08% accuracy for $1,005 compared to Opus 4.6's 0.25% at $8,900.
Explore the implementation on GitHub symbolica-ai/ARC-AGI-3-AgentsGallery - Games Won

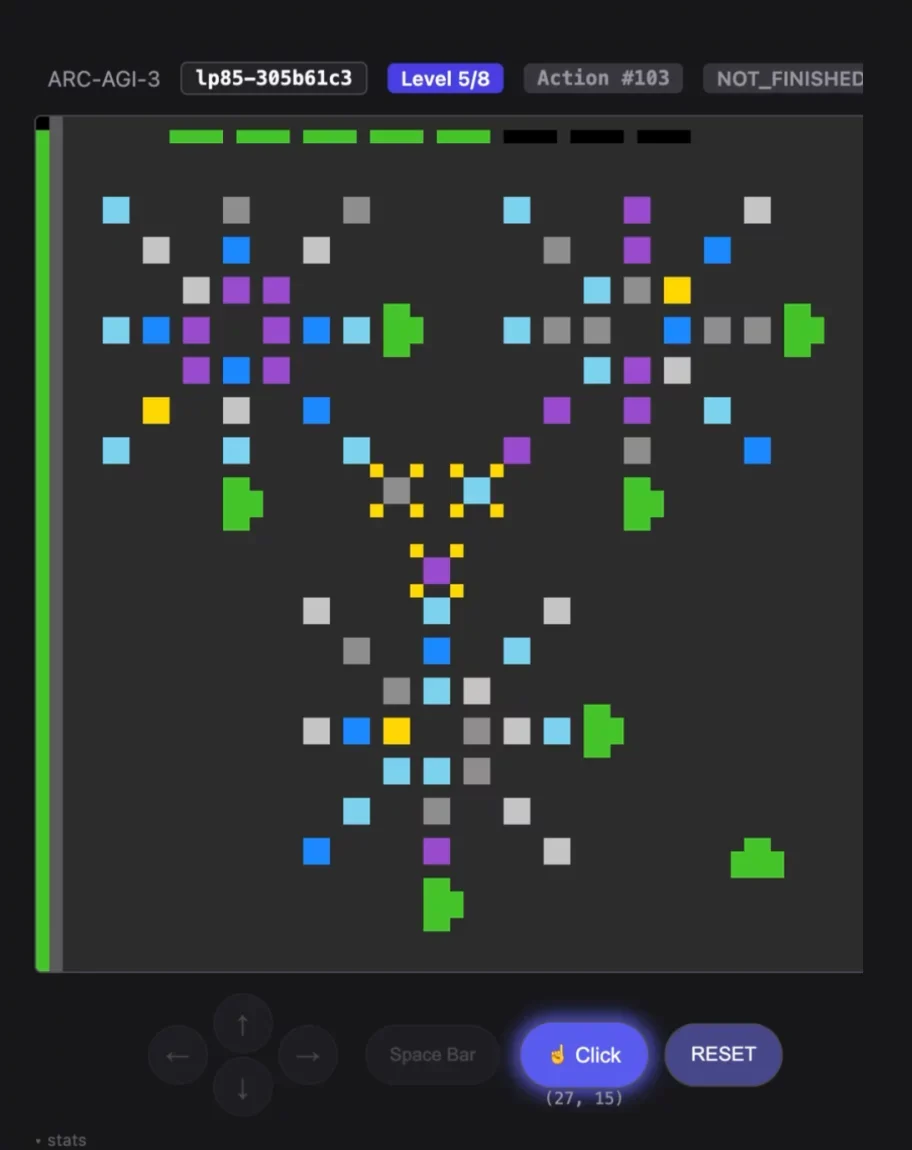
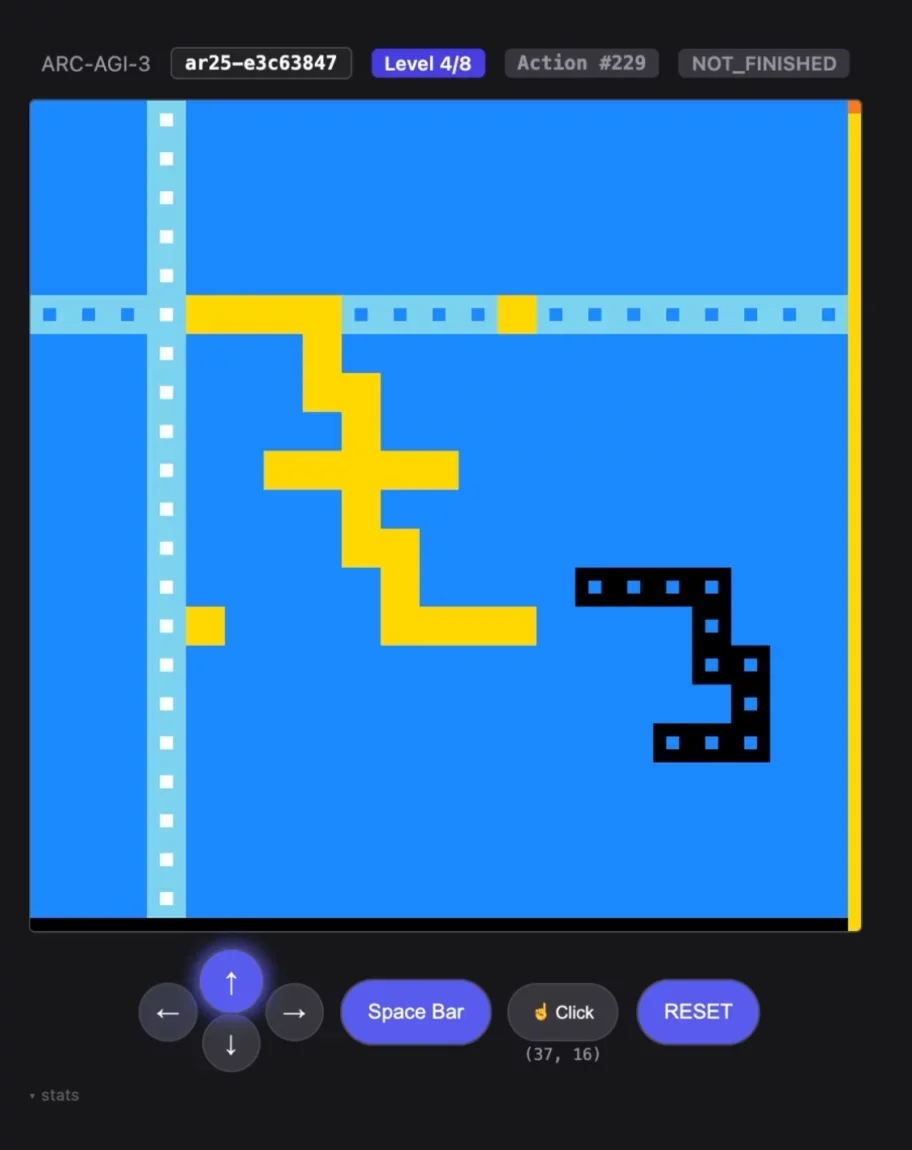
Performance Metrics Across All Sessions
Exceeded human benchmarkVictory achievedSession concluded
Related Articles